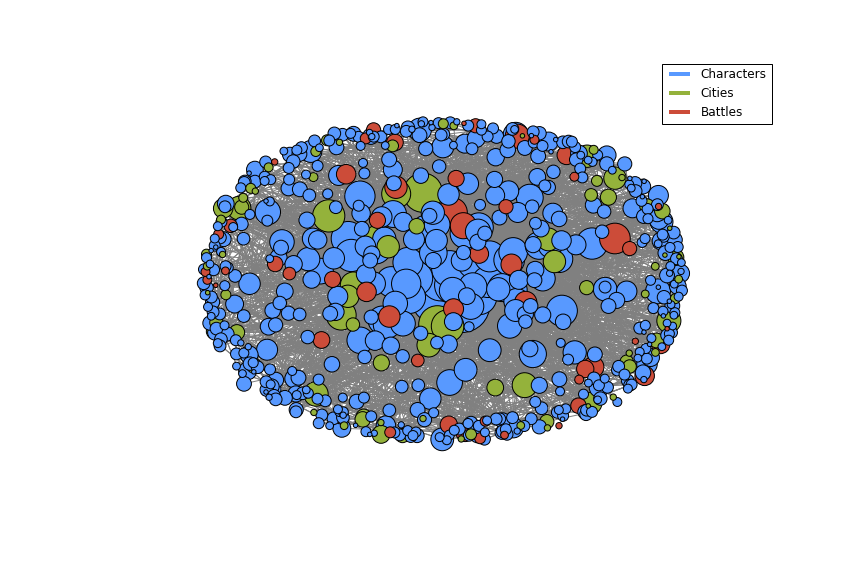
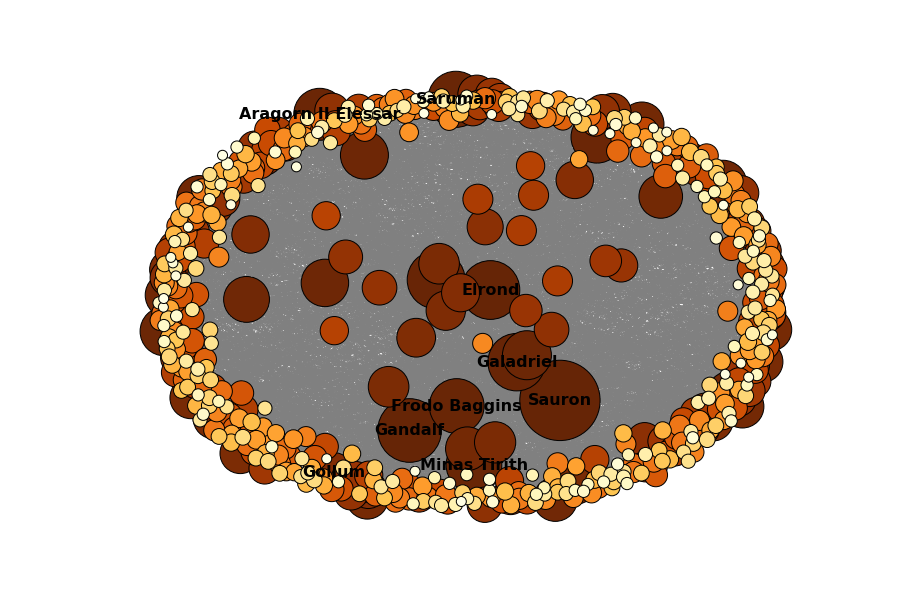
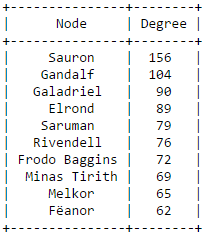
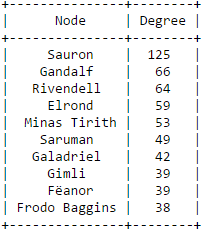
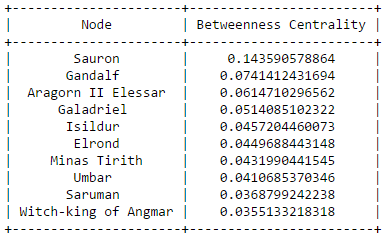
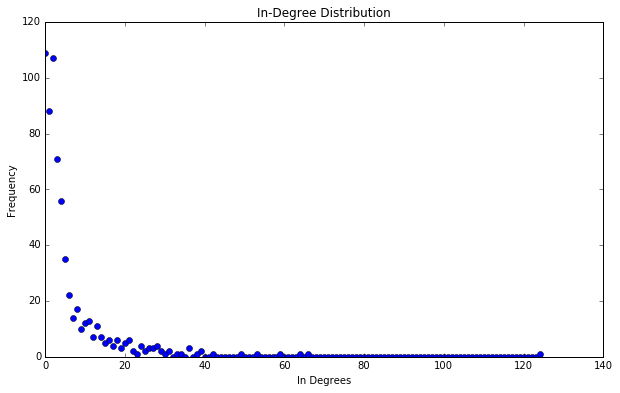
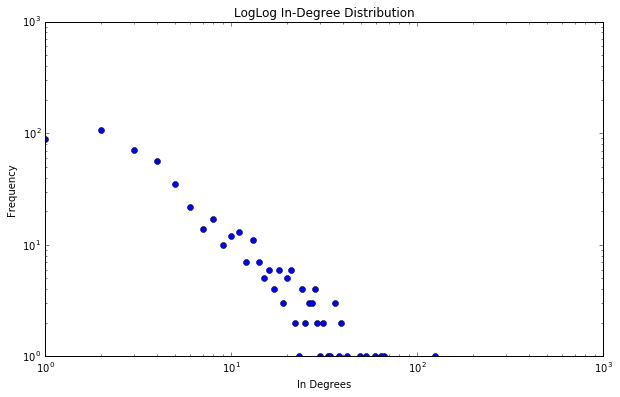
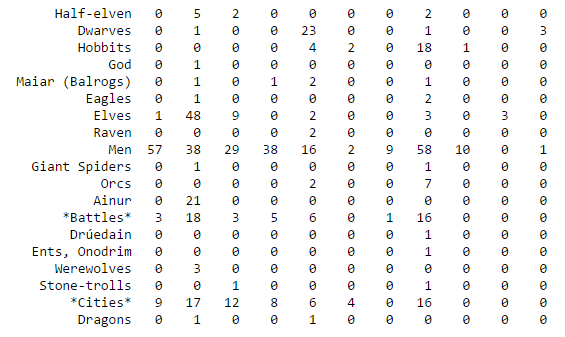
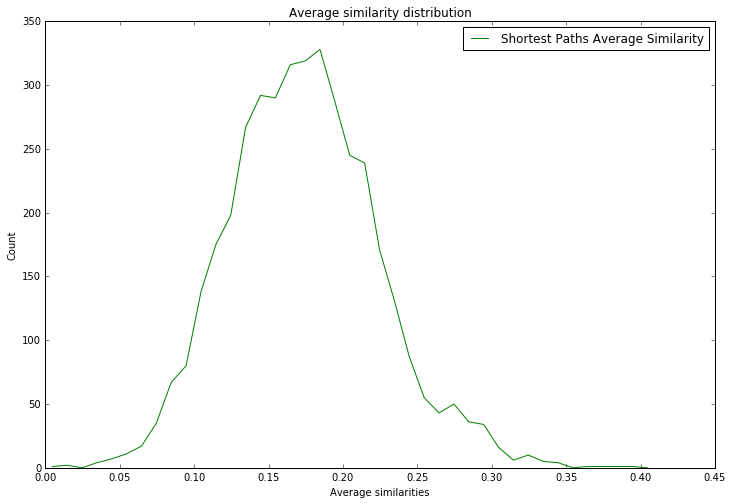
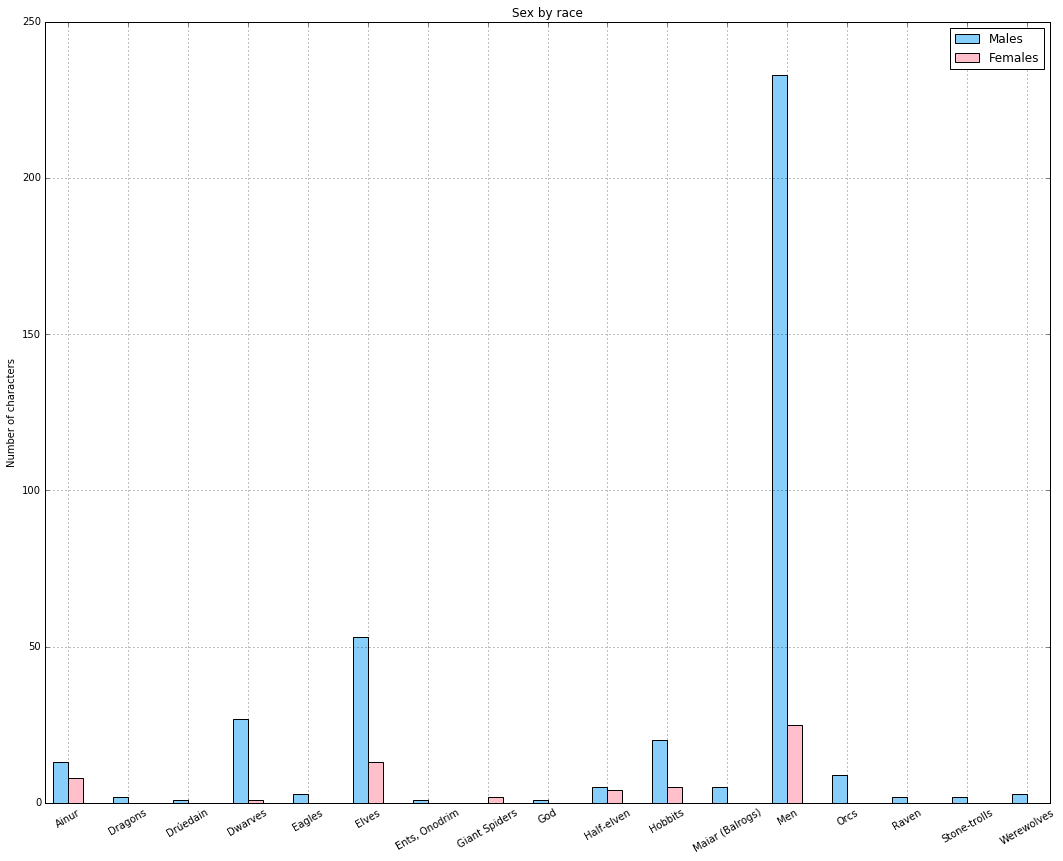
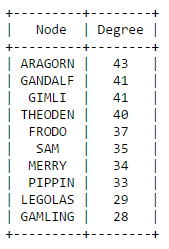
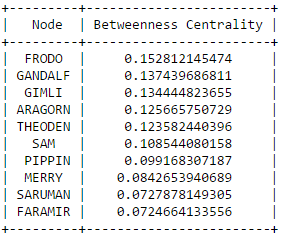
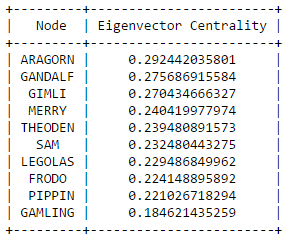
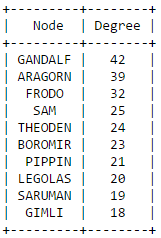
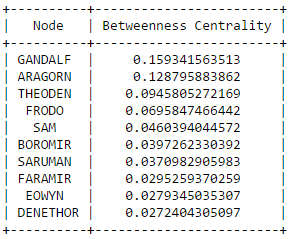
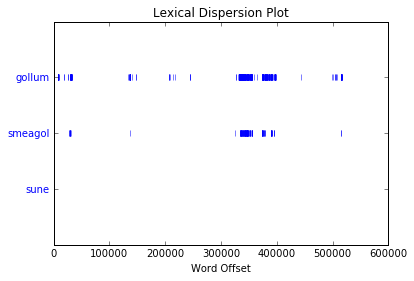
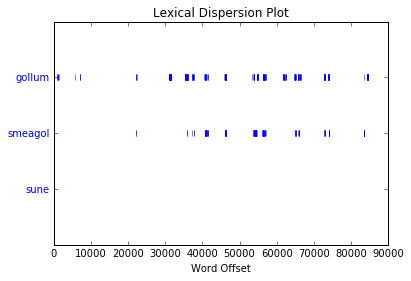
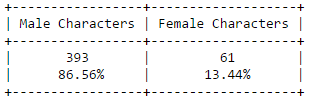The secret behind all those numbers is quite simple: as already mentioned, each row identifies a race, and each column a community. To what degree each race well corresponds to a particular community? It's much easier to understand this with an example. Look at Dwarves row: they have 23 common nodes with the 4th community (remember that indexes start from 0!), and just 0-1 common nodes with the other communities (just one with 3). This is a clear example of well defined community based on the race. Even better the case of the Ainur, who have all their nodes in common with one single community! By the other hand, race of Men is a clearly shows that they don't aggregate well to each other, since they are much more scattered in multiple communities. It's worth saying that, since the original network included battles and cities as well, they are part of the community detection algorithm, and the matrix shows that, if you look at both their rows, they kind of have some similarities: they probably might create a community all together!
In a more scientific way, there is a parameter that is usually took in consideration in order to evaluate to what degree the communities are well defined. Hence, we calculated this parameter, which is known as modularity, both for the Louvain community detection and our version of the algorithm.
-
Louvain algorithm 11 communities, Modularity = ~ 0.74
-
Races algorithm 19 communities, Modularity = ~ 0.33
Yes, ok, let's make it easier... Just keep in mind that the higher the modularity, the better the community are well defined. In conclusion, race might be taken in consideration, but for sure it's not the only thing that marks the different communities.